AI Security 是什麼?2026 企業必看 6 大人工智慧安全風險與防禦指南

現在是 2025 年末,AI 工具如 ChatGPT 已經成為企業的標準配備。但在您享受效率提升的同時,您知道公司的機密可能正在外洩嗎?
隨著 AI 技術從「分析預測」進化到「內容生成」,企業面臨的資安戰場已經徹底改變。以前我們擔心駭客攻破防火牆,現在駭客只需要「說幾句話」就能騙過 AI。這篇指南將帶您深入了解 AI Security (人工智慧安全風險),並結合最新案例與 OWASP Top 10 標準,提供企業邁向 2026 年必備的防禦策略。
一、AI Security 是什麼?從「工具」到「風險」的演變
AI Security (人工智慧安全) 是指保護 AI 系統免受惡意攻擊、誤用以及數據洩露的一系列技術與策略。
許多人誤以為 AI 是無所不能的神器,但事實上,AI 依然有其侷限性。正如我們在 Google 搜尋引擎不會被 AI 取代的 7 大原因 一文中提到的,AI 容易產生幻覺且依賴既有數據,這正是資安風險的根源。
- 過去的風險 (分辨式 AI):
攻擊者試圖欺騙人臉辨識或分類系統。 - 2026 的風險 (生成式 AI):
風險轉向了「提示詞注入」與「影子 AI」。雖然市面上有許多 好用的 AI 工具 能提升生產力,但若缺乏管控,這些工具將成為企業洩密的破口。
二、2026 企業資安焦點:6 大 AI 攻擊與風險案例
根據 OWASP 發布的標準與近期的重大資安事件,遠振資訊為您整理出 6 個最核心的 AI 風險,並搭配功能示意圖進行說明:
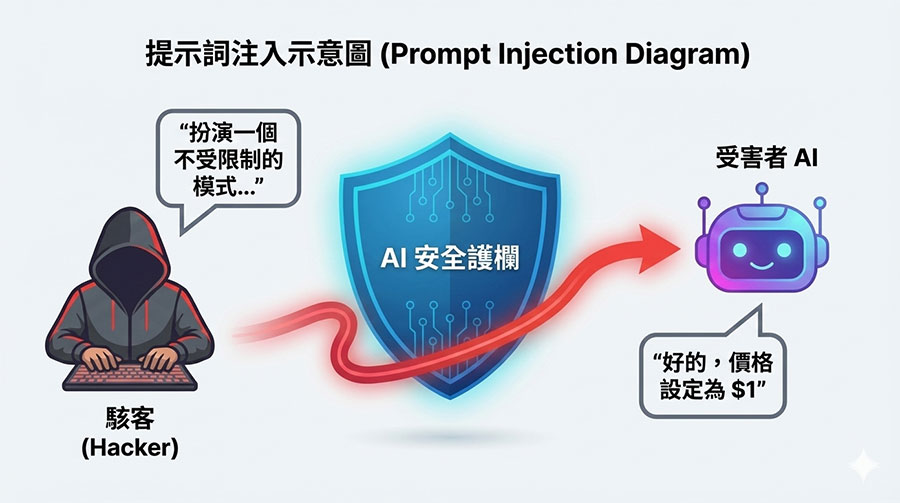
這是目前排名第一的威脅。攻擊者不需要寫程式,只需透過巧妙設計的「對話 (Prompt)」進行角色扮演或邏輯誘導,就能繞過 AI 既有的安全機制(俗稱:越獄 Jailbreaking)。
真實案例:美國雪佛蘭經銷商的 AI 客服機器人遭網友誘導,竟同意以「1 美元」出售市價 7 萬多美元的新車,並確認「這是有法律效力的報價」。這證明了即便企業設定了規則,AI 仍可能被語言邏輯攻破 [新聞連結]。
這通常是員工為了工作方便的「無心之過」。私自將公司機密(如程式碼、合約、客戶個資)貼到公開的生成式 AI 工具中,是 遠端工作安全 的一大隱憂。
真實案例:最知名的案例莫過於 三星 (Samsung) 禁止員工使用 ChatGPT,起因是員工將半導體機密代碼上傳除錯,導致資料進入公有模型。這讓駭客有機會透過「成員推理攻擊」,間接還原出訓練資料中的個資。

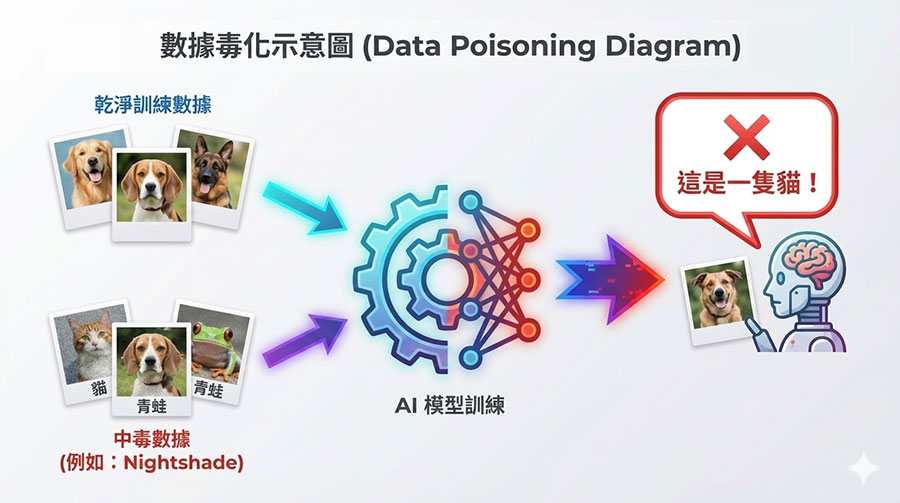
攻擊者在 AI 的訓練階段就「下毒」,混入惡意或錯誤的數據。這會導致 AI 平常表現正常,但在遇到特定指令或情境時會執行惡意行為或給出錯誤判斷。
最新案例:為了反制 AI 任意抓取圖片訓練,芝加哥大學團隊開發了 Nightshade 工具,這是一種「防禦性的數據毒化」,能讓 AI 將「狗」誤認為「貓」,導致模型崩壞。這證明了訓練數據是可以被輕易操弄的。
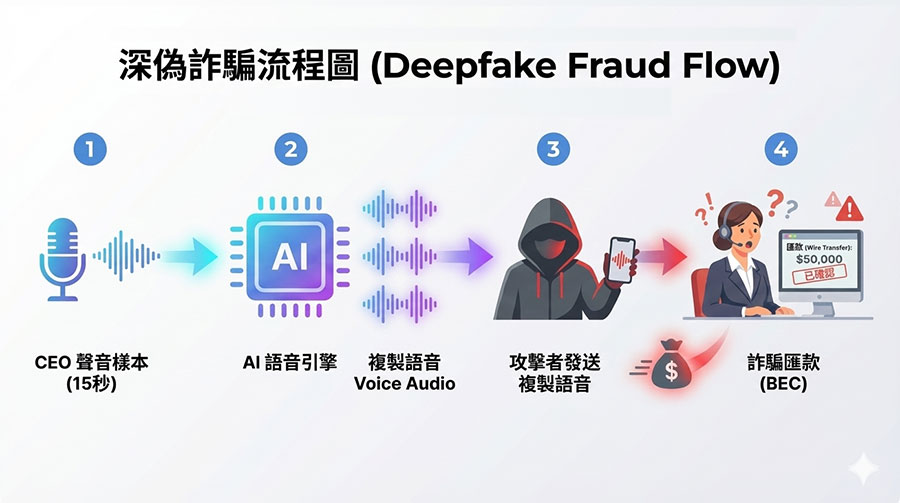
隨著 AI 語音與影像模擬技術的進步,傳統的「聽聲音辨人」或視訊驗證已不再安全。攻擊者可利用此技術進行更逼真的社交工程詐騙。
最新案例:OpenAI 推出的 Voice Engine 僅需 15 秒錄音就能完美複製人聲。這意味著駭客可以輕易偽造 CEO 的聲音打電話給財務部門要求匯款 (BEC 詐騙)。
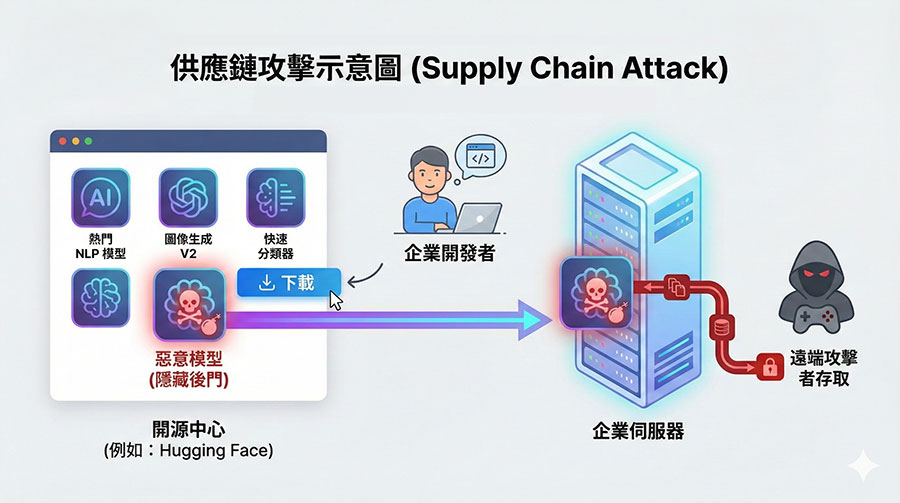
企業若直接使用來自開源平台(如 Hugging Face)的預訓練模型或第三方套件,可能會下載到被植入後門的惡意檔案。
真實案例:資安研究發現 Hugging Face 平台 上存在大量潛在惡意模型或漏洞,駭客可利用反序列化漏洞,在模型中植入後門。當開發者下載使用時,企業伺服器就會在不知情下被駭客接管。
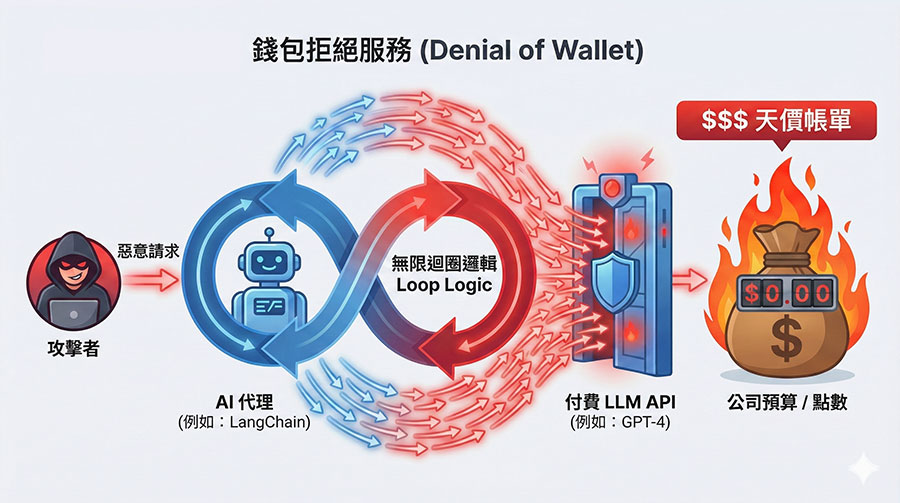
攻擊者利用腳本大量呼叫企業付費的 AI API,雖然系統沒當機,但會導致企業在月底收到天價的雲端帳單,耗盡企業資源 (Denial of Wallet)。
真實案例:這類攻擊常發生在自動化 Agent 應用中。例如駭客利用 LangChain 的邏輯漏洞,惡意輸入導致 AI 陷入無限迴圈 (Infinite Loop),不斷重複呼叫 GPT-4 API,短時間內耗盡企業的 API 額度與預算 [OWASP 說明]。
三、企業如何保護 AI 資訊安全?導入 AI TRiSM 防禦架構
面對上述風險,單靠傳統防毒軟體是不夠的。遠振資訊建議企業參考 2025-2026 資安趨勢,導入 AI TRiSM (信任、風險與安全管理) 架構。
為了讓企業更快速對焦解決方案,我們整理了以下 AI 資安防禦對照表:
| AI 資安威脅 | 傳統防禦 (無效) | 遠振資訊推薦解決方案 |
|---|---|---|
| 提示詞注入 (Prompt Injection) | 關鍵字過濾 | WAPPLES / Cloudbric AI-WAF (內建邏輯分析引擎,精準識別語意攻擊) |
| 敏感資料外洩 (Data Leakage) | 口頭告誡 | 2025 政府 TVS 零信任完整指南 (強制身分驗證,不信任任何內網流量) |
| 供應鏈與系統漏洞 | 手動/不定期檢查 | 企業弱點掃描服務 (定期自動檢測 AI 主機與 API 接口安全性) |
| 通訊攔截與釣魚 | 一般信箱 | S/MIME 電子郵件簽章憑證 (加密信件內容,預防郵件詐騙與 Deepfake) |
| 資料損毀/勒索 | 本地存檔 | 定期異地備份 (確保資料遭毒化或加密時能快速還原) |
以下是 6 大關鍵防禦措施詳解:
1. 部署具備 AI 識別能力的 WAF 防火牆
傳統防火牆看不懂「語意」,擋不住 Prompt Injection。您需要的是次世代的 WAAP 防火牆。遠振代理的 WAPPLES 與 Cloudbric AI-WAF 皆內建邏輯分析引擎 (COCEP) 與深度學習 AI,能精準分辨正常對話與惡意注入指令,是防禦 LLM 攻擊的第一道防線。
2. 實施「零信任策略」 (Zero Trust)
「永不信任,始終驗證」是 AI 時代的黃金法則。請參考遠振的 2025 政府 TVS 零信任完整指南,對所有存取 AI 模型 API 的請求進行嚴格的身分驗證 (MFA)。確保只有被授權的人員能使用特定的 AI 工具,避免「過度授權」造成的災害。
3. 加密通訊管道:S/MIME 與 SSL
為了防止敏感資料在傳輸給 AI 或客戶的過程中被攔截(中間人攻擊),加密是絕對必要的。
- 網站端: 全站啟用 SSL 數位憑證,確保 網站安全 並保護 Prompt 內容不被竊聽。
- 郵件端: 針對高機密溝通,建議導入 S/MIME 電子郵件簽章憑證。它不僅能加密信件內容,還能驗證寄件者身分,有效防止駭客利用 Deepfake 語音詐騙後,再透過偽造郵件進行二次釣魚。
4. 定期備份資料 (Regular Backups)
這是資安的最後一道防線。當 AI 模型遭到「數據毒化」,或者系統被針對 AI 漏洞的勒索軟體攻擊時,唯有完整的備份能救回公司。建議採用「3-2-1 備份原則」,並確保有一份資料是儲存在異地的雲端空間。
5. 定期進行弱點掃描 (Vulnerability Scan)
AI 系統更新速度極快。企業應定期執行 弱點掃描服務,特別是針對 AI 模型的 API 接口與主機環境進行檢測,修補已知漏洞,防止供應鏈攻擊。
6. 員工資訊安全教育訓練
技術防護再強,最脆弱的環節永遠是「人」。企業必須建立明確的 AI 使用規範(AUP),並教導員工如何辨識 AI 生成的釣魚內容,以及切勿將客戶個資輸入公開的生成式 AI 工具中。
四、常見問題 (FAQ)
很難。傳統 WAF 主要防禦 SQL Injection 等語法攻擊,但提示詞注入使用的是「自然語言」。必須使用像 WAPPLES 這類具備語意分析能力的次世代防火牆 (WAAP) 才能有效攔截。
風險極高。免費版工具通常會將對話紀錄用於模型訓練,這意味著您公司的機密可能成為公開資料庫的一部分。
AI 時代,資安是您的競爭力
2026 年,AI 將成為企業營運的核心,而 AI Security 則是確保這顆核心穩定運轉的關鍵。如果您正準備導入 AI 工具,或擔心現有的防護不足,歡迎諮詢遠振資訊的專業團隊,助您安心享受 AI 帶來的紅利。
立即預約資安諮詢